データプライバシー、セキュリティ、効率的なリソース配分の重要性が高まる中、ファイルタイプの検出は組織にとって重要でありながら見過ごされがちな課題です。人工知能(AI)は、機械学習を使用して偽装ファイルを検出できるため、MetaDefender プラットフォームのコアコンポーネントであるファイルタイプ検証に革命をもたらしています。これにより、従来の静的スキャンソリューションよりもはるかに高いレベルの効率で動作しながら、検出精度を高めることができます。
ファイルタイプ偽装のテクニック
ファイルの拡張子を変更する(例えば、.exeを.txtに変更する)ことは、以前は一般的な手口であったが、セキュリティ・ソリューションはこのような基本的なトリックを見分けることに長けてきた。そのため、攻撃者はより手の込んだ手法に手を染めるようになった。最新のファイルタイプ偽装は、単純な拡張子操作にとどまりません。攻撃者はファイルの内部構造を操作し、正規のファイルタイプを模倣することができます。
攻撃者にとっての真の挑戦は、単にファイルを偽装するだけでなく、ユーザーを騙して実行させることにある。ソーシャル・エンジニアリングの手口は、しばしばここで登場する。攻撃者は、馴染みのあるアイコンや名前でファイルを偽装し、ユーザーを誘い込んでファイルを開かせるかもしれません。あるいは、ファイルの種類に関係なく自動実行を可能にするソフトウェアの脆弱性を悪用することもある。
場合によっては、なりすましファイルが手の込んだ多段階攻撃の一部になることさえある。一見無害に見えるファイルが、本物の悪意のあるペイロードをターゲット・システムにダウンロードまたはインストールする可能性があります。
ファイルタイプの偽装は、あらかじめ定義された悪意のあるコードのパターンに依存する従来のシグネチャベースの検出方法を回避するため、重大なリスクをもたらします。この欺瞞的な手法は、ランサムウェア、トロイの木馬、ワームなど、さまざまな脅威を配布するために使用できます。
正確なファイルタイプ検出が重要な理由
組織のセキュリティの要であるファイル・フィルタリングについて考えてみよう。ファイルの種類を正確に識別することで、組織は悪意のあるファイルを効果的にブロックすることができます。これにより、マルウェアのようなインバウンドの脅威から保護すると同時に、機密情報のアウトバウンドフローを防止してプライバシーを強化することができます。さらに、エンターテイメント・メディアのような非本質的なファイルをフィルタリングすることで、リソースの利用が最適化されます。これは、HIPAA規制により、サイバー攻撃からデジタルヘルスケアデータを保護するために、強力な患者データ保護が義務付けられているヘルスケアにおいて特に重要です。信頼性の高いファイルタイプの検出は、ファイル・フィルタリングのコンプライアンスを成功させるためのバックボーンを形成します。
ファイルタイプ検出の重要性は、ファイルのフィルタリングだけにとどまらない。ウイルススキャナは、スキャンに優先順位をつけるために、ファイルタイプ検出を活用することがよくあります。歴史的にウイルスとは関係のないファイルタイプを効率的に識別することで、スキャナはリスクの高いファイルにリソースを集中させ、悪意のある脅威の検出を迅速に行うことができます。
正確なファイルタイプの検出は、以下のようなさまざまなセキュリティやデータ管理の実践において、舞台裏で重要な役割を果たしている:




ファイル検証の3つの主な方法
| 方法 | 長所 | 短所 |
| ファイル拡張子 | 素早く簡単:ファイルの拡張子をチェックし、素早く識別します。 ほとんどのオペレーティングシステムで使用可能。 | 簡単に騙される:攻撃者は悪意のあるファイルを無害な拡張子にリネームすることができる。 非標準の拡張子には制限があり、拡張子がオプションである Linux/Unix では信頼できない。 |
| マジックバイト | より信頼できる:特定のバイトパターン(マジックバイト)に依存して識別するため、拡張子よりも精度が高い。拡張子のないバイナリファイルも識別可能。 | 制限付き:マジックバイトが定義されているファイルタイプに対してのみ機能します。すべてのファイルタイプにマジックバイトがあるわけではない。攻撃者がなりすましのためにマジックバイトを変更する可能性がある。異なるソースからの一貫性のない情報は混乱を引き起こす可能性がある。 |
| キャラクター分布分析 | 欺瞞を暴く:実際のコンテンツを解析して真のファイルタイプを明らかにし、無害な拡張子を装った隠れたマルウェアを暴露する可能性があります。テキストファイルの種類(例:プレーンテキストかコードか)に関する貴重な洞察を提供します。 | 計算コストが高い:ファイル内容の読み取りと分析が必要なため、他の方法より遅い。ユニークなファイル内容や不規則なファイル内容の場合、誤検出の可能性がある。明確な文字分布のないバイナリファイルでは効果が限定的。 |
OPSWAT AIを活用してファイルタイプを正確に検出する方法
精度と安全性を高めるため、OPSWAT File Type Verification 。 MetaDefender Coreのワークフローを活用することで、これらの方法を独自の強力で効率的なフィルタリングプロセスに統合します。最高の精度を達成しながら、処理時間を短縮します。
また最近、特にテキストベースのファイルの課題に対処するために、機械学習による検出を追加しました。ログファイル、スクリプトファイル、readmeファイルなど、これらのファイルはすべて単なる「テキスト」であり、他の方法では明確な特徴がありません。正確な分類には、内容の分析が非常に重要です。テキストベースのファイルを誤って分類すると、悪意のあるスクリプトファイルが検出されずに実行される可能性があり、危険です。
MetaDefender Core でテキストベースのファイルタイプ検証を設定する。
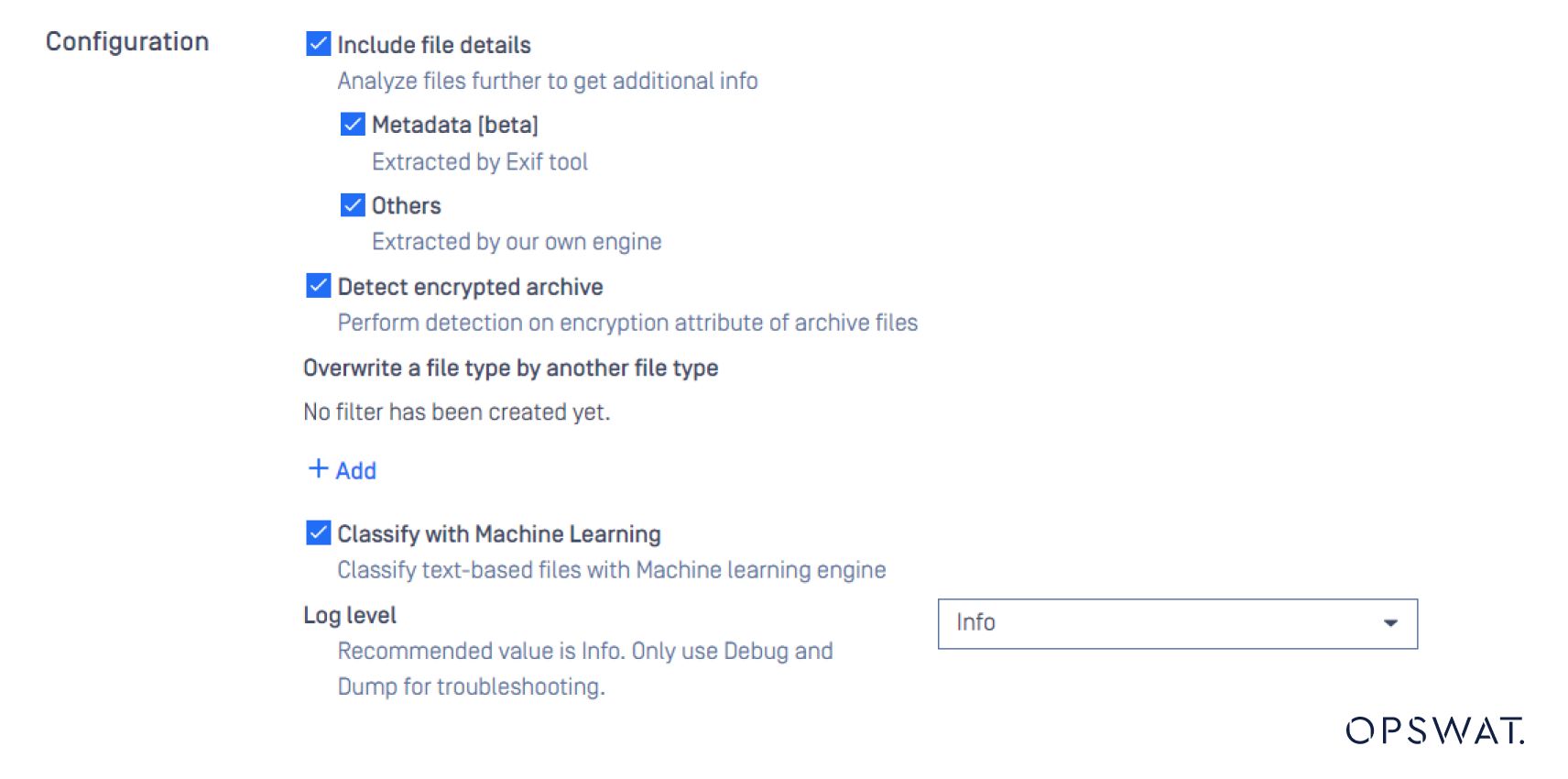
どのように機能するか、この例を見てみよう。
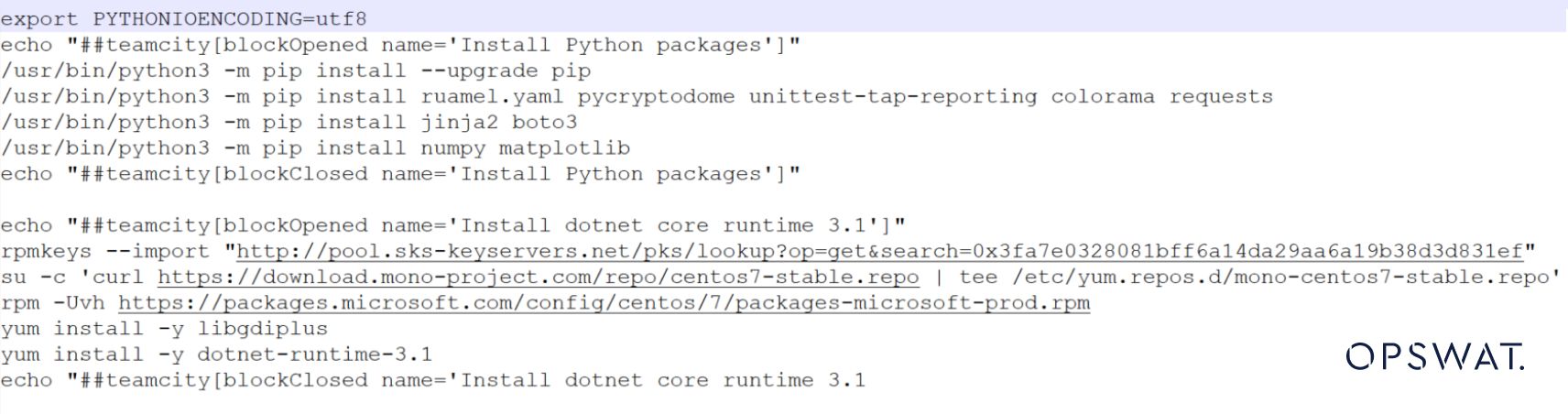
ファイルタイプの検出におけるAIの有無の比較をご覧ください。
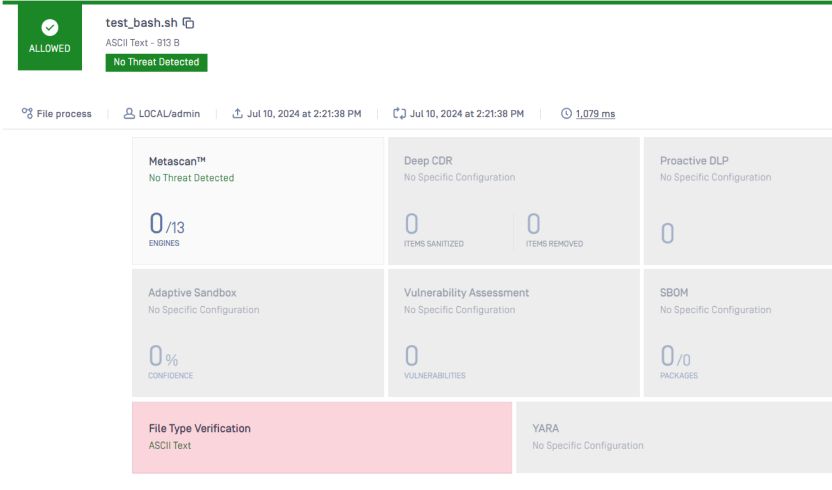
面白いことに、下のサンプルのように、シェル・ファイルの上部に短い説明を書くように変更することができる。
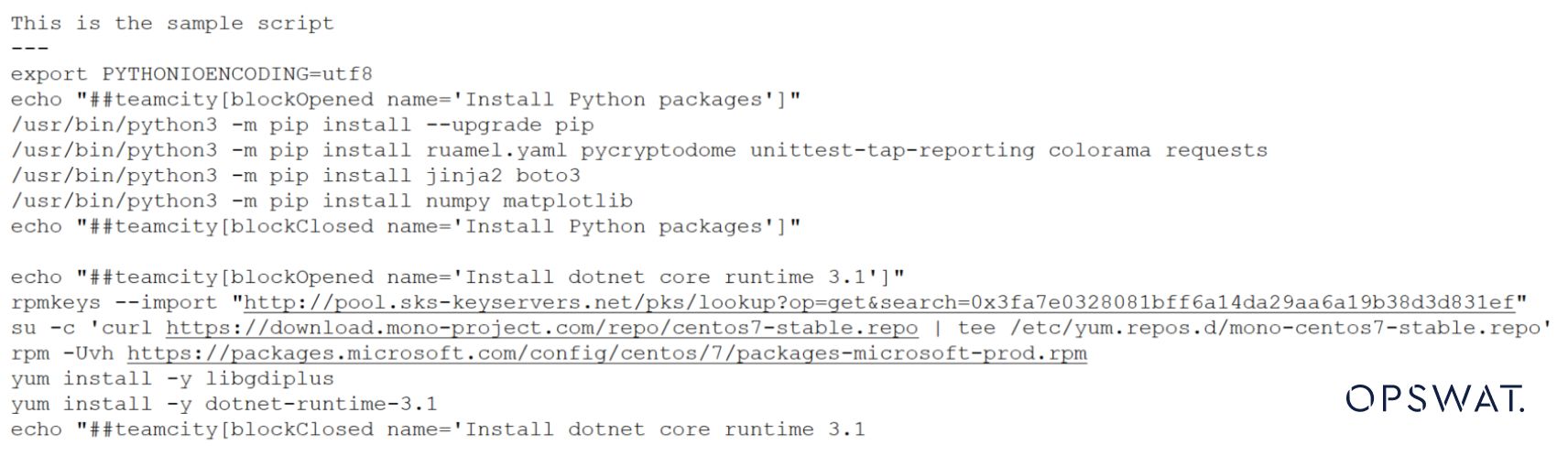
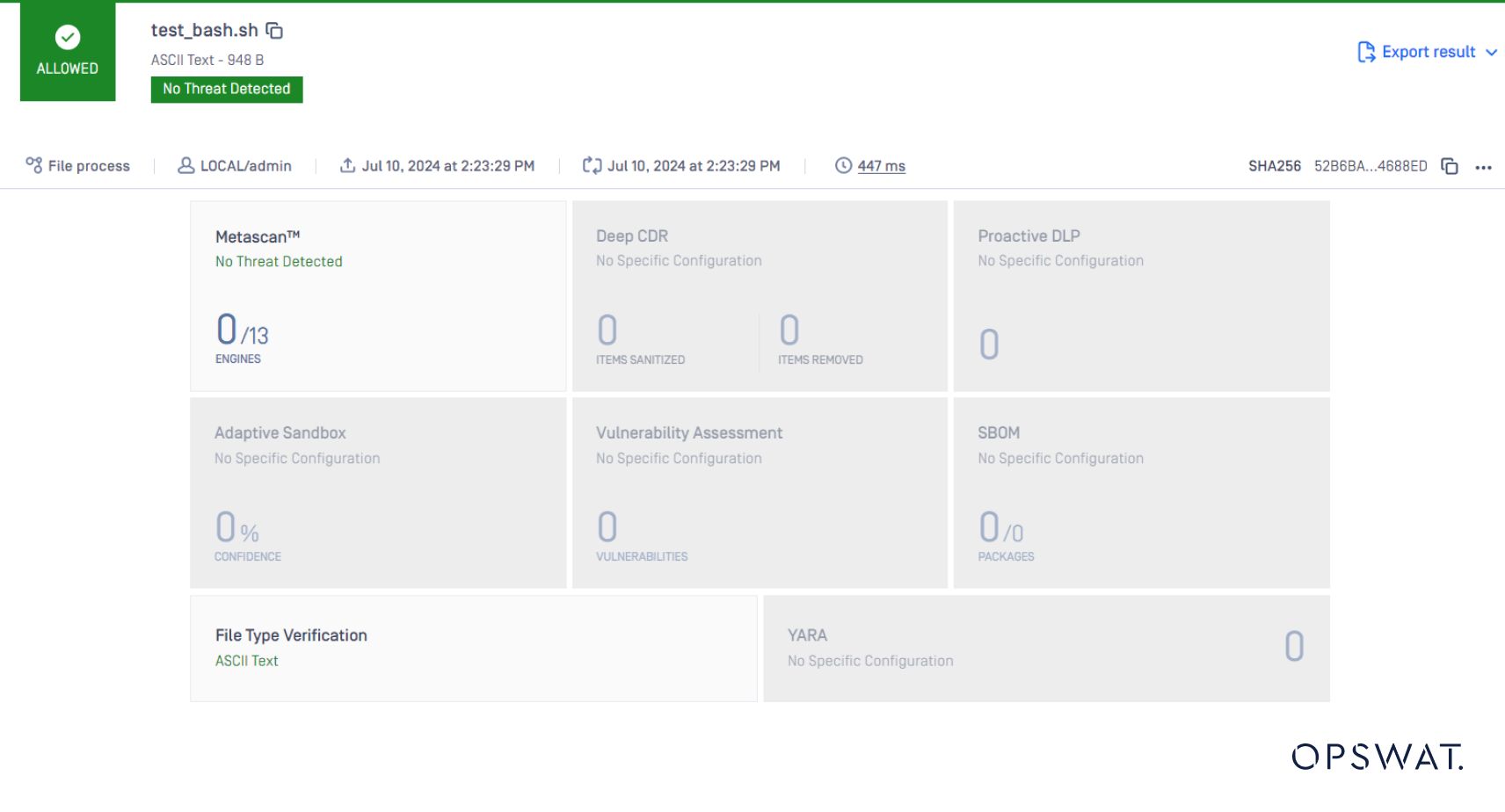
ファイルタイプは再びテキストとして検出されます。これはもはやスクリプトではない。
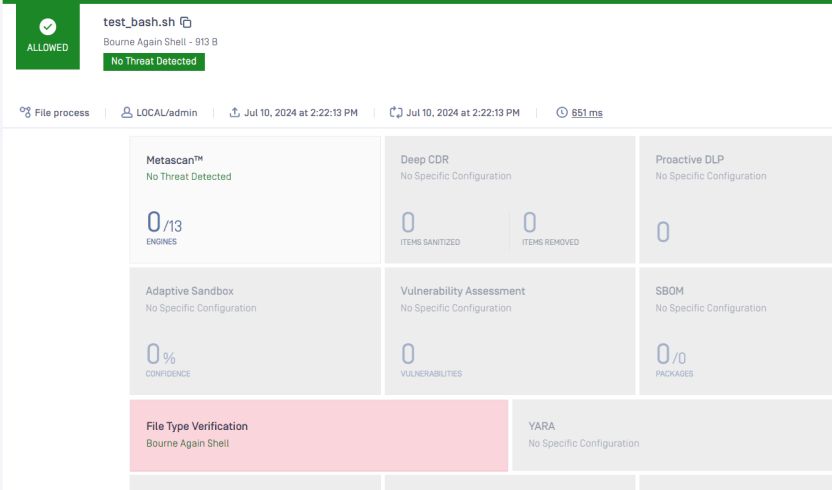
下の画像のように、この2行をコメントアウトしてそのままにしておく。
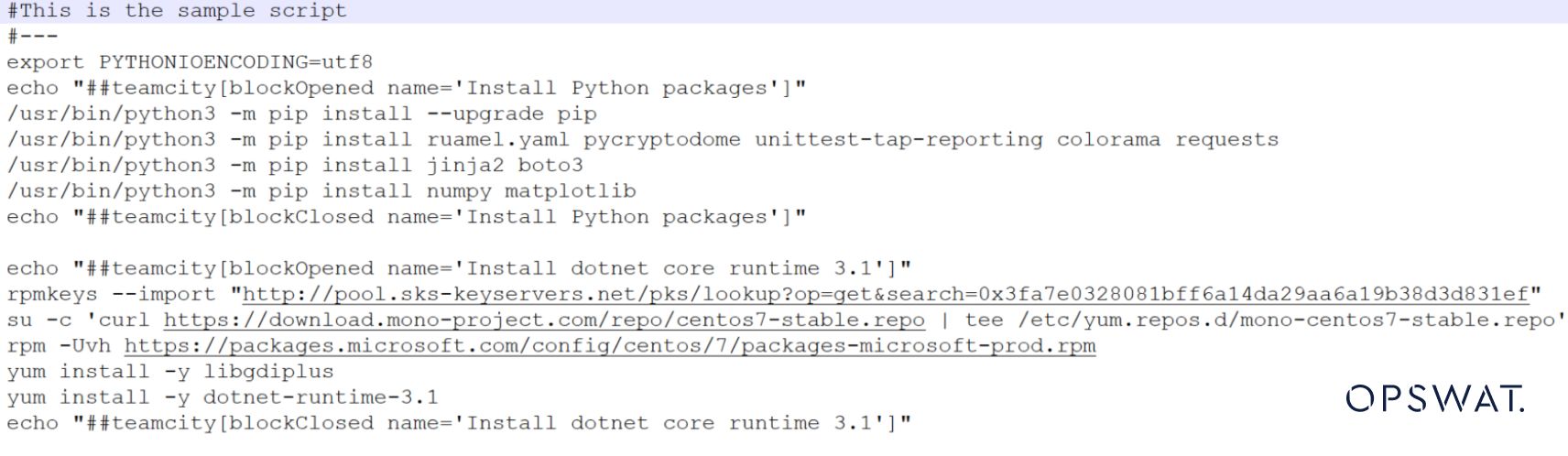
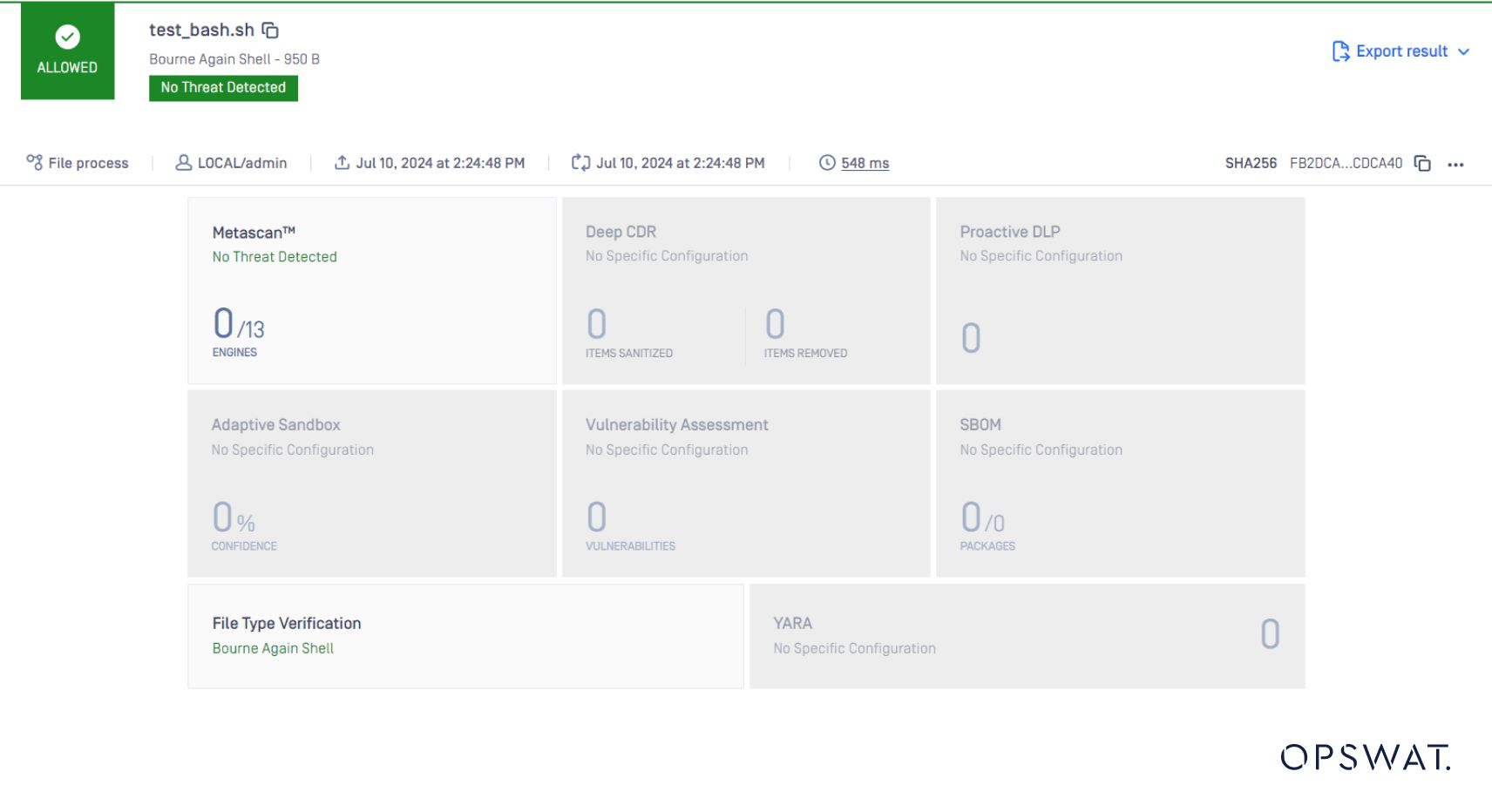
ファイルタイプはこうでなければならない:
テキストベースのファイル分析にディープラーニングを活用することで、OPSWAT File Type Verification :
- 精度の向上 - AIモデルは、特にテキストベースのファイルにおいて、最も巧妙なファイルタイプの偽装を識別することができます。
- 将来性のあるセキュリティ - 新たな脅威への適応能力により、継続的な保護が保証されます。
- 効率の向上 - 正確な検出により、手作業による分析の必要性が減り、時間とリソースを節約できます。
おわりに
正確なファイルタイプの検出は重要な防御の第一線を形成するが、AIの強化を伴うOPSWAT File Type Verification 、企業はセキュリティ体制をさらに強化することができる。この高度なソリューションを、ファイル媒介型マルウェア対策や機密データ保護などの他のセキュリティ対策と並行して活用することで、企業はファイルタイプ偽装の脅威やデータ侵害から組織を守る多層防御を実現することができます。
詳細については、サイバーセキュリティの専門家にご相談ください。

